Genomsökning (Crawling): Grunden för all SEO
Innan Google kan indexera eller ranka en sida måste den först upptäckas. Det kan låta självklart, men det är en punkt som många förbiser när de fokuserar på innehåll, backlinks eller tekniska detaljer. Om Googlebot aldrig hittar sidan spelar resten ingen roll. Genomsökning är därför startpunkten i hela sökmotorns process – det är den fas som avgör om ditt innehåll över huvud taget får en chans att synas i sökresultaten.
Google har inte något komplett register över alla webbsidor i världen. Det är snarare tvärtom: webben förändras konstant, och Google måste därför ständigt leta efter nytt och uppdaterat innehåll. Detta innebär att hela internet i praktiken är ett dynamiskt ekosystem där Google försöker hålla sitt index så aktuellt som möjligt genom kontinuerlig och strukturerad genomsökning.
Innehåll
- Hur Googlebot hittar och samlar in webbsidor
- Automatiska “spindlar” som navigerar webben
- Länkbaserad upptäckt – kärnan i Googles modell
- XML-sitemap som genväg för Google
- Googles system och algoritmer bakom genomsökningen
- En enorm distribuerad infrastruktur
- Hur Googlebot prioriterar
- Sidans popularitet
- Uppdateringsfrekvens
- Risken för att innehåll ska bli inaktuellt
- Crawl Rate Limit: Googles inbyggda säkerhetssystem
- 1. HTML-crawling
- 2. Rendering
- SEO-konsekvens
- Rekommendation
- Crawl Budget: När det blir ett verkligt SEO-problem
- Vanliga problem som äter upp crawl budget
- 1. Oändliga filter-URL:er
- 2. Duplikat från session-ID eller trackingparametrar
- 3. Interna sökresultat och paginerade sidor
- 4. Facetterad navigering som skapar 500+ kombinationer
- Vanliga problem som äter upp crawl budget
- Hur du analyserar Googles crawling av din webbplats
- Google Search Console: Crawl Stats (Googles egen insyn i hur de crawlar dig)
- Antal sidor Google crawlar per dag
- Svarstider och serverhälsa
- Eventuella fel (t.ex. 5xx, timeout, redirect-loopar)
- Vilken typ av Googlebot som har besökt sajten
- Vilka filtyper Googlebot hämtar
- Serverloggar: Den mest detaljerade analysen du kan få (avancerat men kraftfullt)
- Fördelar med logganalys
- Crawl Stats vs Serverloggar: När använder man vad?
- Google Search Console: Crawl Stats (Googles egen insyn i hur de crawlar dig)
- Snabb hosting = mer crawling från Google
- SEO-åtgärder för att optimera crawl budget
- Minimera skräp-URL:er
- Snabba upp servern
- Se till att viktiga sidor är helt öppna
- Sammanfattning: Crawling som förutsättning för indexering och ranking
Hur Googlebot hittar och samlar in webbsidor
Automatiska "spindlar" som navigerar webben
För att upptäcka nytt innehåll använder Google automatiska botar – ofta kallade spindlar. Googlebot är Googles mest kända crawler, och dess uppgift är att läsa av webbsidor ungefär på samma sätt som en användare skulle göra, men i en mycket större skala. Den hämtar HTML, följer länkar och bygger en intern karta över hur sidor hänger ihop.
Ett enkelt sätt att tänka på Googlebot är att se den som en extremt snabb användare som:
Klickar på länkar
Besöker undersidor
Samlar in information
Dokumenterar allt den hittar
Länkbaserad upptäckt – kärnan i Googles modell
Googlebot använder framför allt länkar som vägledning. Den går från sida till sida i en kedjereaktion. Ett typiskt scenario kan se ut så här:
Googlebot hämtar startsidan på en sajt.
Den hittar länkar i navigeringen, i sidfoten och i brödtexten.
Varje länk blir en potentiell ny URL att genomsöka.
Dessa sidor innehåller i sin tur fler länkar.
Det är så Google ”utforskar” webben.
Om en ny sida saknar interna länkar – till exempel en ny produkt, ett nytt blogginlägg eller en kampanjsida – kan det dröja mycket längre innan den upptäcks. I praktiken blir sidan nästan osynlig, även om den är publicerad.
Kort exempel:
En e-handel publicerar en ny produktsida, men glömmer att lägga den i kollektioner, menyer och interna länkar. Trots att sidan är online hittar inte Google den eftersom den saknar ingångar.
XML-sitemap som genväg för Google
En XML-sitemap fungerar som en ”officiell lista” över en sajts viktigaste sidor. Den är inte lika kraftfull som intern länkning, men den hjälper Google att snabbare identifiera:
Nya sidor
Viktiga sidor som ligger djupt i strukturen
Sidor som inte är starkt internlänkade
Google garanterar inte att varje URL i sitemapen indexeras, men den påskyndar upptäckten, vilket är särskilt värdefullt för stora sajter eller sajter med ofta uppdaterade produktkataloger.
Exempel:
En blogg med 3 000 artiklar där äldre artiklar ligger djupt i strukturen kan med en sitemap säkerställa att Google känner till alla URL:er, även om internlänkningen är svag.
Googles system och algoritmer bakom genomsökningen
En enorm distribuerad infrastruktur
Google har utvecklat ett avancerat crawlingsystem som konstant arbetar i bakgrunden. Redan i Googles tidiga forskningsrapporter från 1998 betonades att sökmotorn är byggd för att ”effektivt genomsöka och indexera webben”. I dag sker denna genomsökning via en global infrastruktur bestående av tusentals datorer som parallellt hämtar miljarder webbsidor.
Hur Googlebot prioriterar
Google använder flera signaler för att bestämma:
Vilka sajter ska besökas
Hur ofta de ska crawlas
Hur många URL:er som ska hämtas per besök
Även om algoritmerna är hemliga vet vi att följande faktorer spelar roll:
1. Sidans popularitet
Sidor med många länkar eller hög trafik crawlas mer frekvent.
T.ex.: En nyhetsartikel som delas viralt kan crawlas flera gånger samma dag.
2. Uppdateringsfrekvens
Sidor som Google vet förändras ofta får tätare besök.
T.ex.: Startsidor, e-handelssidor med lagernivåer, eller bloggar som publicerar dagligen.
3. Risken för att innehåll ska bli inaktuellt
Även om en sida är liten och inte populär kommer den förr eller senare att crawlas igen, för att Googles index inte ska bli gammalt.
Crawl Rate Limit: Googles inbyggda säkerhetssystem
Googlebot är designad för att inte överbelasta servrar. Därför finns en automatisk ”hastighetsgräns” som anpassas dynamiskt.
Så fungerar det i praktiken
Om servern ger snabba svar → Googlebot ökar crawl-hastigheten.
Om servern blir långsam, visar fel eller upplever belastning → Googlebot bromsar.
Om sajten upplever 5xx-fel → crawl minskas drastiskt.
Exempel:
En WordPress-sajt på billig hosting går från 200 ms till 2 sekunder svarstid när en kampanj lanseras. Google noterar fördröjningen och minskar crawlingen tills serven är stabil.
Du kan i Search Console begränsa crawl-hastigheten, men du kan inte tvinga Google att crawla snabbare än vad deras system anser säkert.
Googlebot och JavaScript: Modern crawling i två faser
Många moderna sajter bygger nästan allt innehåll med JavaScript (t.ex. React, Vue, Angular). Google klarar av detta, men processen är mer resurskrävande och sker i två steg:
1. HTML-crawling
Först hämtas HTML-koden. Om sidan är tom vid första laddning (SPA-arkitektur) ser Google bara ett skelett.
2. Rendering
Google renderar därefter sidan med en headless Chromium-webbläsare. Då körs alla script och dynamiska komponenter. Först då kan Google läsa:
Produktlistor
Blogginlägg
Navigationsmenyer
Internt genererat innehåll
SEO-konsekvens
Rendering sker senare, ibland flera dagar efter första crawlningen.
Det innebär att JavaScript-tungt innehåll ofta indexeras långsammare.
Exempel:
En React-baserad produktsida laddar priset först via API-anrop. Google måste rendera sidan för att se priset, vilket skjuter upp indexeringen.
Rekommendation
Placera viktigt innehåll i HTML eller använd server-side rendering, annars riskerar du att Google missar kritisk information.
Crawl Budget: När det blir ett verkligt SEO-problem
För mindre sajter är crawl budget oftast irrelevant. Men när en sajt blir stor – eller när den genererar massor av URL-varianter – är det här en av de viktigaste tekniska SEO-frågorna.
Google definierar crawl budget som:
”Antalet URL:er Google kan och vill crawla under en viss tidsperiod.”
Den består av två komponenter:
1. Crawl Rate Limit
Hur mycket servern klarar av.
2. Crawl Demand
Hur intressant Google tycker din sajt är, baserat på:
Trafik
Länkar
Uppdateringsfrekvens
Indexeringsbehov
Vanliga problem som äter upp crawl budget
1. Oändliga filter-URL:er
Exempel:/skor?sort=pris&färg=svart&storlek=42&page=5
2. Duplikat från session-ID eller trackingparametrar
Exempel:/produkt/soffa?session=38FD91
3. Interna sökresultat och paginerade sidor
Exempel:/search?q=soffa&page=12
4. Facetterad navigering som skapar 500+ kombinationer
Exempel:
Färg × Storlek × Pris × Varumärke = tusentals meningslösa URL:er.
Hur du analyserar Googles crawling av din webbplats
Att förstå hur Google crawlar din sajt är lika viktigt som att förstå att den gör det. För att kunna optimera crawlability, identifiera flaskhalsar och upptäcka problem i tid behöver du se den faktiska datan bakom Googles besök.
Det finns två huvudsakliga källor:
Google Search Console (Crawl Stats) – lättillgänglig och väldigt insiktsfull
Serverloggar – mer avancerat men ovärderligt för teknisk SEO i större skala
Båda visar olika typer av data och kompletterar varandra.
Google Search Console: Crawl Stats (Googles egen insyn i hur de crawlar dig)
Google Search Console (GSC) erbjuder en dedikerad rapport som heter Crawl Stats, där du kan se exakt hur Googlebot beter sig på din webbplats.
Du hittar den under:
Inställningar → Crawl stats (Genomsökningsstatistik)
Här får du en detaljerad överblick över:
Antal sidor Google crawlar per dag
Detta visar:
Om Google crawlar tillräckligt ofta
Om crawling plötsligt har minskat (vilket kan tyda på problem)
Om större strukturella ändringar påverkar crawlvolymen
Exempel:
Lanserar du 5 000 nya produktsidor och ser ingen ökning i crawlvolymen under kommande dagar, då har du ett problem med crawl budget eller intern länkning.
Svarstider och serverhälsa
GSC visar Googles uppmätta responstid för varje URL den hämtar.
Långsamma svar kan visa:
Hostingproblem
Överbelastning
Dålig caching
Tunga skript eller bilder
Eftersom Googlebot minskar sin crawling vid långsamma svar är detta en av de viktigaste datapunkterna för teknisk SEO.
Eventuella fel (t.ex. 5xx, timeout, redirect-loopar)
Rapporten listar alla fel Google stött på, t.ex.:
5xx-fel – servern svarar inte
4xx-fel – URL:en existerar inte
Oändliga redirect-kedjor
Blockeringar av robots.txt
Ser du många serverfel bör du agera direkt — detta kan begränsa din crawling i veckor framåt.
Vilken typ av Googlebot som har besökt sajten
Google använder flera varianter av Googlebot:
Desktop
Mobile
Imagebot
AdsBot
Detta kan visa om:
Google testar indexering på ny enhet
Din sajt hanterar mobilt innehåll korrekt
Bildsökningar crawlas regelbundet
Vilka filtyper Googlebot hämtar
Du ser om Google crawlar:
HTML
CSS
JavaScript
Bilder
Videor
Detta är ovärderligt för JavaScript-tunga sajter där man vill säkerställa att Google faktiskt hämtar alla script som krävs för att rendera sidan.
Serverloggar: Den mest detaljerade analysen du kan få (avancerat men kraftfullt)
Serverloggar är det råa dataformatet där varje enskilt besök till din server loggas — även Googles. Detta är den mest detaljerade och tekniskt exakta metoden för att analysera crawling.
I loggarna hittar du bl.a.:
Varje besök av Googlebot
Vilken URL som hämtades
Exakt tidpunkt
User-agent
Svarskod (200, 404, 503…)
Bandbredd
IP-adress
Fördelar med logganalys
Du ser exakt vad Googlebot gör – inte bara sammanfattningar
Loggarna visar varje crawl-händelse, vilket gör att du kan se:
Vilka sidor som får mycket eller lite crawl
Om Google missar viktiga sidor
Om stora delar av sajten aldrig besöks
Om Google fastnar i filter, parametrar eller interna sökresultat
Exempel:
En stor e-handel upptäckte att Googlebot besökte tusentals filter-URL:er per dag, men nästan aldrig deras viktigaste kategorisidor – ett klassiskt crawl budget-problem som bara loggarna avslöjar.
Du kan avslöja falska Googlebot-besök
Många botar utger sig för att vara Googlebot. Med logganalys och IP-verifiering kan du:
Validera att det verkligen är Google
Blockera skadliga botar som äter bandbredd
Förstå varför servern belastas
Du ser hur JavaScript och assets crawlas
Loggarna visar om Google verkligen hämtar:
JS-filer
CSS
Produktbilder
Video-URL:er
Detta är kritiskt för:
React/Vue/Angular-sajter
Sidor med lazy-loaded innehåll
E-handel med dynamiska API-anrop
Du kan mäta effekten av SEO-åtgärder direkt
Till skillnad från Search Console, som ibland har fördröjning, är loggarna i realtid.
Exempel:
Efter att du lagt interna länkar till en viktig kategori kan du se om Google börjar crawla den mer redan samma dag.
Om du åtgärdar 5xx-fel kan du se när Google återvänder till normal crawlvolym.
Crawl Stats vs Serverloggar: När använder man vad?
Här är en enkel tabell som hjälper användaren förstå skillnaden:
| Verktyg | För vem? | Styrkor | Svagheter |
|---|---|---|---|
| Google Search Console | Alla | Visuellt, lätt att förstå, officiell Google-data, trendgrafer | Mindre detaljrik, viss fördröjning |
| Serverloggar | Tekniska SEOs, stora sajter | 100% exakt data, realtid, avslöjar problem GSC missar | Kräver tillgång till server, tekniska verktyg och logganalys |
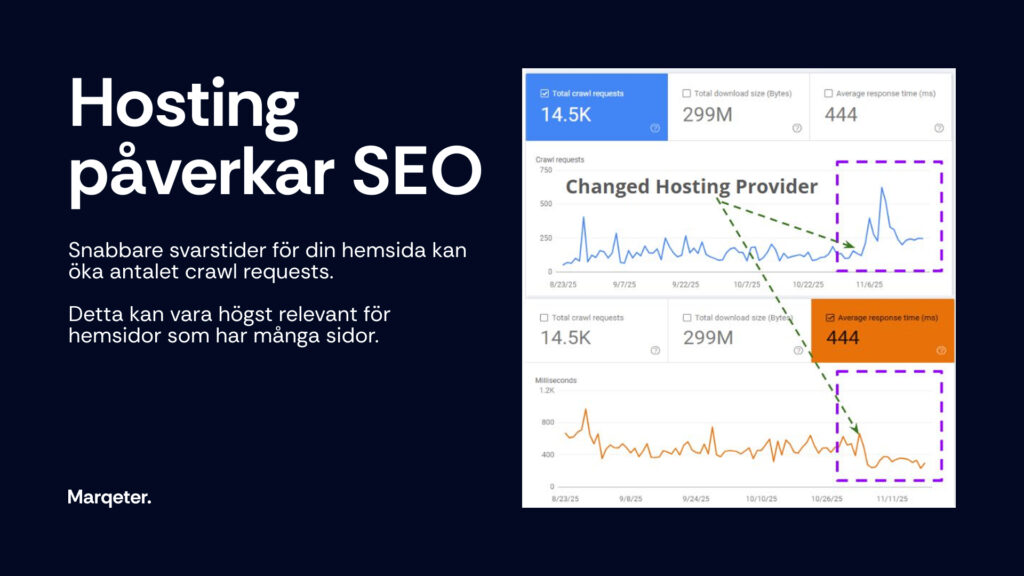
Snabb hosting = mer crawling från Google
En av de viktigaste – men mest förbisedda – faktorerna för hur ofta Google crawlar din webbplats är serverns svarstid. När webbplatsen laddar långsamt minskar Google automatiskt crawl-hastigheten för att inte riskera att belasta servern. Men när du förbättrar hastigheten sker det motsatta: Google vågar öka antalet crawl requests.
Grafen här visar ett tydligt exempel: efter ett byte till en snabbare hosting ökade antalet crawl requests omedelbart. För webbplatser med många sidor (t.ex. e-handel, media, kataloger eller SaaS-portaler) kan ett hostingbyte vara skillnaden mellan att Google upptäcker nya sidor samma dag – eller flera veckor senare.
Snabb server = snabbare genomsökning = snabbare indexering.
En av de mest direkta tekniska SEO-vinsterna du kan få.
SEO-åtgärder för att optimera crawl budget
Här är de praktiska insatserna du kan göra:
1. Minimera skräp-URL:er
Blockera lågkvalitativa filter i robots.txt
Använd canonical för dubbletter
Sätt noindex på interna sökresultat
Eliminera session-ID i URL:er
2. Snabba upp servern
Använd CDN
Optimera bilder och CSS/JS
Aktivera caching
Uppgradera hosting om nödvändigt
3. Se till att viktiga sidor är helt öppna
Kontrollera att:
Inga misstag i robots.txt hindrar crawl
Inga relevanta sidor har råkat få noindex
Sidor inte kräver inloggning
Innehållet inte ligger bakom formulär eller klick
Exempel:
En butik har en kampanjsida som endast kan öppnas efter att användaren klickat ”Visa erbjudande” → Google kommer aldrig åt sidan.
SEO-åtgärder för att optimera crawl budget
Här är de praktiska insatserna du kan göra:
1. Minimera skräp-URL:er
Blockera lågkvalitativa filter i robots.txt
Använd canonical för dubbletter
Sätt noindex på interna sökresultat
Eliminera session-ID i URL:er
2. Snabba upp servern
Använd CDN
Optimera bilder och CSS/JS
Aktivera caching
Uppgradera hosting om nödvändigt
3. Se till att viktiga sidor är helt öppna
Kontrollera att:
Inga misstag i robots.txt hindrar crawl
Inga relevanta sidor har råkat få noindex
Sidor inte kräver inloggning
Innehållet inte ligger bakom formulär eller klick
Exempel:
En butik har en kampanjsida som endast kan öppnas efter att användaren klickat ”Visa erbjudande” → Google kommer aldrig åt sidan.
Sammanfattning: Crawling som förutsättning för indexering och ranking
Genomsökningen är fundamentet för allt SEO-arbete.
Om Google inte kan:
hitta
ladda
förstå
eller navigera
… ditt innehåll, blir resten av SEO-strategin meningslös.
En bra crawl-strategi bygger på:
Tydlig intern länkstruktur
Optimerad prestanda
Ren och kontrollerad URL-struktur
Tillgängligt och renderbart innehåll
Minimalt med skräp-URL:er
Rätt användning av robots.txt och noindex
Ju enklare du gör det för Googlebot att ta sig runt på din sajt, desto mer komplett blir indexeringen och desto större chans får din sajt att ranka.

Faustas Nazarovas
“Jag ser SEO som en vetenskap – inte en trend. För mig handlar det inte om gissningar, utan om att förstå mönstren, matematikens logik och människans beteende bakom varje sökresultat.”